徹底解説:利益を最大化するデータ基盤のつくり方とそのプロセス




DATAFLUCTは、2022年2月9、10日の2日間、オンラインイベント「Data Cross Conference(データクロスカンファレンス)」を開催しました。データに基づいたビジネスモデルの変革方法について学ぶもので、「あらゆる企業、人がデータを有効に活用し、より良い意思決定をできる世界へ」がテーマです。
初日のセッションでは「データ基盤による利益最大化と初期構築プロセス」と題し、データ活用によって億単位の利益を創出してきた風音屋のゆずたそ氏 が登壇。データ基盤の構築を目指す方に向けて、費用対効果を最大化するための初期構築プロセス (https://speakerdeck.com/yuzutas0/20220209) を紹介しました。
データ基盤がもたらす恩恵
講演は「われわれはなぜデータ基盤をつくるのか」というゆずたそ氏の問い掛けから始まり、ゆずたそ氏が、解明していくという流れで進みます。この記事では、第1部としてゆずたそ氏による解説をレポートします。
データ基盤は、幅広いデータを活用するために構築する必要のあるものです。社内外のデータを収集して使いやすい形式に整え、蓄える場所を提供し、各部門がさまざまなデータ活用施策を実行できるようになります。例えば、マーケティング分野においては、特にクーポン・広告の配信などに大きな効果を発揮します。
広告の配信の仕方を考えるとき、クリック数やアクセス数だけを求めていると、だんだん来てほしい層にマッチしない広告になっていき、本当に来てほしい顧客が離れていくという問題があります。
解決策として、分析するデータの幅を広げて、より顧客の課題に合った広告配信を実践したところ、顧客が使い続けてくれるようになったケースがありました。
営業の現場でも、データ基盤を最大限に活用できます。誇大広告など無理に契約を獲得した場合にクレームが入ったり、解約されたりなど結局企業として望ましくない結果になってしまうことがあります。一方で、多くの場合、営業のインセンティブは獲得件数だけをもとに与えられるので、こうした「長期的な利用につながらない契約」が考慮されないままインセンティブが支払われてしまいます。
そこでデータの幅を広げ、契約獲得件数だけでなく、その後の履歴や売り上げなどの顧客データも紐付けて分析した上でインセンティブを計算する方法に変えたところ、営業の仕方が変わっていったという事例もあります。
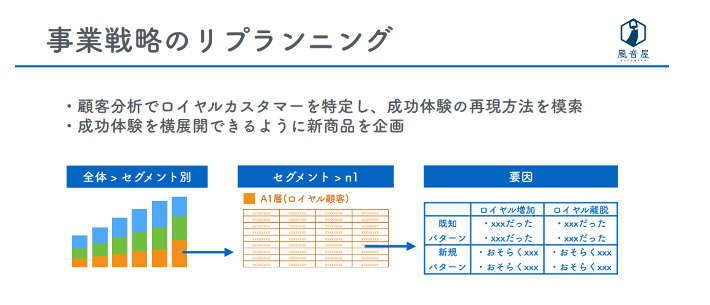
このほか、データ基盤の導入によって、これまで専門チームが3人がかりで2日間かけていた売り上げ要因分析を10分でできるようになり、ロイヤルカスタマーの傾向から新たな商品開発を企画できるようになるなど、素早いアクションと大きな結果につながった事例もあります。
このように、単一部門の手元データだけでは絶対に分析できないことを実現できるのが、データ基盤がもたらす恩恵です。ビジネス全体に影響をおよぼすことができるのです。
毎日データを見るための環境整備が不可欠に
多くの企業が、データの活用を検討する際に、「まずはExcelで手元にあるデータ分析しよう」と考えがちですが、それではデータ活用の成功体験は積めません。
これは、ReturnとInvestmentという2つの観点から説明できます。
まずReturnですが、Excelで「分析ゴッコ」を1回試したとしても、都合良くインサイトがみつかることはまずありません。それよりも、経営者がトップセールスで得た勘や経験、度胸、いわゆる「KKD」を信じた方が、短期的には利益の創出に役立ちます。
Investmentの問題は、コストの問題です。Excelで試そうとしても、そのデータを誰かが用意しなくてはなりません。そのデータを用意するための基盤は存在しないため、用意することが難しく、迅速に、安定的にデータを抽出できないということになってしまうのです。
それよりも、データ基盤の活用について、毎日データを見る環境の整備の方がカギを握ります。例えば、今日の売り上げがいくらか、1年前、1週間前、前日と比べて増えているかなどを把握し、説明ができないのであればデータ整備ができていないと考えます。
データ分析に使われるツールといえばExcelですが、Excelを使っている限りは成功体験はいつまでも積み上げられません。なぜなら、時間をかけて分析したからといってその結果から都合よく求める要因が見つかるわけではないからです。経営者のトップセールスや勘の方が短期的には優れていることも多いです。
それに、Excelで分析しようにも「持ってくるデータがない」、データはあっても「持ってくるのに時間がかかる」という状態では、迅速な分析を安定的に実施できません。
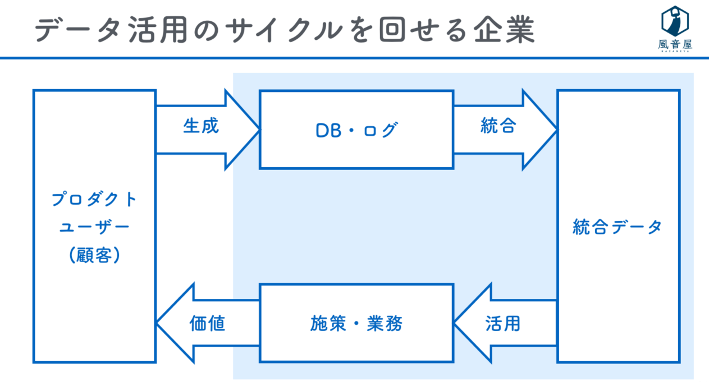
図のように、データ活用のサイクルを回せる企業は、ユーザーが生成したデータをデータベースに格納し、統合した上で活用して施策を実施します。そこで生み出した価値をさらにユーザーに還元するわけです。
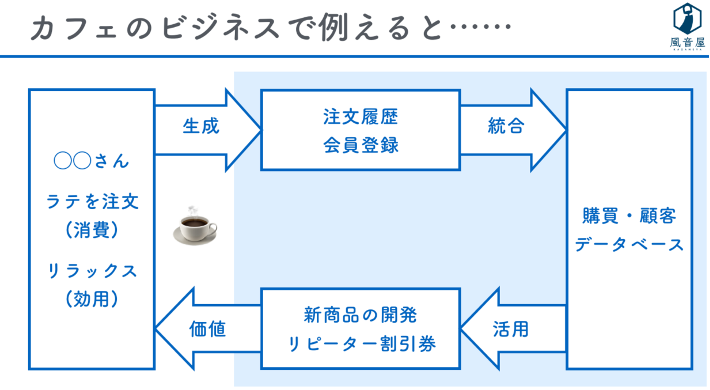
カフェのビジネスに例えましょう。いまAさんという顧客がいるとします。カフェラテを注文することで、カフェでリラックスするという効用が得られます。その結果、カフェラテを注文したというデータが生成され、統合することで購買や顧客データベースが生成できます。それを活用することで、人気商品、人気が落ちている商品を把握、分析して新商品を開発したり、過去の注文履歴に応じてリピーターに割引券を発行するといったサービスを展開できたりします。その結果、「またお店に行ってみよう」といった行動を引き起こすことができます。これが、データ活用のサイクルを回すことの意図です。
ROIを説明できない問題と2つのアプローチ
データ基盤を構築しようとするときにROI(Return On Investment:投資利益率)について、経営者やステークホルダーに対して説明できないという問題があります。必要性があることはわかっていても、投下した費用に見合う効果があるのかということです。
これに対するアプローチには2つあります。
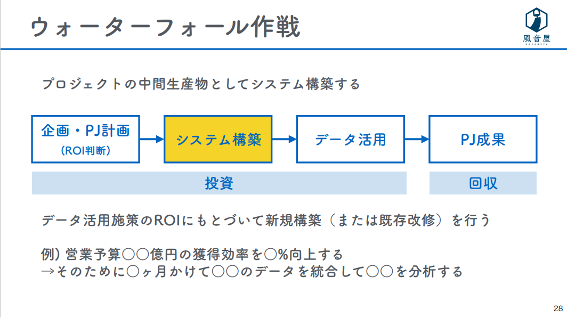
1つ目は「ウォーターフォール作戦」で、プロジェクトの中間生産物としてシステム構築を位置づける方法です。システム構築とデータ活用は投資額の一部としてとらえられるようになるため、プロジェクトでもくろむ利益額に見合うかどうかを判断できます。
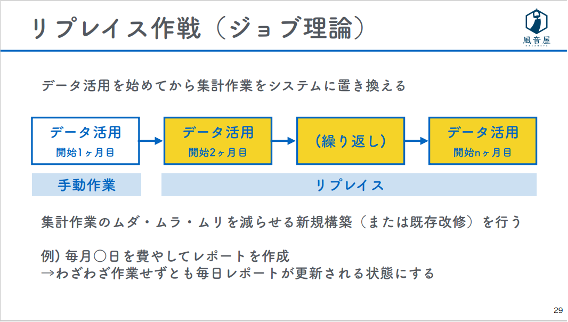
2つ目は「リプレイス作戦」です。取りあえず、データ活用を手作業で初めてみます。すると、時間がかかるのでムダ・ムラ・ムリが表面化します。省力化作業として次第にその過程を自動化していけば、最終的にはデータ基盤の構築ができるという流れです。
これら2つの方法は別々ではなく、組み合わせて実行することもあるかもしれません。このような活動を部分的に繰り返していくことで全体的にデータ基盤が整備され、データを継続的に利用できる文化が定着します。
企業規模別でROIを最大化するアプローチ
データ基盤のROIを最大化するアプローチには、企業規模別に次のような4つがあります。
デベロッパー不在の組織
スプレッドシートで基盤を作ります。生データを直接加工しないなどいくつかのルールのもと、デベロッパーがシステムを設計するのと同じ発想でシートを設計します。目的に合わせた適切な設計をすると、適切に使えるシステムが構築できます。この発想であれば、デベロッパーがいなくてもデータ基盤を構築できます。
大企業やメガベンチャー
リターンとしての改善インパクトを重視します。扱うデータ量の規模が大きく、処理に特別な手法が必要となる案件では、節約は難しく、それよりも業務改善のインパクト・リターンを重視します。セキュリティなども考慮に入れる必要があります。
スモールビジネス
「デファクトスタンダードとベストプラクティスに乗る」ということで、あまりカスタマイズしないほうがよいことが強調されます。大企業やメガベンチャーとは反対に、節約重視です。世の中に発表されているシステム事例は大企業のものが多いですが、必ずしもこれに倣う必要はないでしょう。
スタートアップ
早く作って、早く直すことが重要です。スタートアップはデータ量が少なく短時間で構築・修正できるので、ROIは比較的気にしなくてもよいでしょう。コストを気にし過ぎてスキルの低い人に依頼したり、カスタマイズにこだわったりすると、かえって話がこじれて失敗します。
スタートアップにとって重要なのは、最高のシステムを作ることではなく、良いサービスを作って顧客を増やしていくことです。
セッション第2部:データ基盤はなぜ必要か
セッションの第2部では、DATAFLUCTの代表取締役・久米村隼人が「データ基盤はなぜ必要か」というタイトルで講演しました。
データ基盤が必要となってきた背景には、AIや機械学習がビジネスで広く利用されるようになり、活用できるデータの種類が増加してきたことがあります。以前から社内で発生していたデータに加え、画像データや社外データなどが当たります。
現在、これらのデータは意志決定をするための材料だけでなく、営業活動の評価や顧客へのレコメンド、さらにはこれらを併せ持った新たな価値を創り出すためのものなど、活用範囲は広がりつつあります。
これに伴い、データの分析基盤はレベルアップを求められるようになりました。「構造化データから非構造化データ」に、「バッチ処理からリアルタイム処理」へと需要の種類は変化しています。
データ基盤はSoI(System of Insight)というモデルで、「データレイク基盤」と「データ分析基盤」からできています。
「データレイク基盤」は、SoR(System of Record)と呼ばれる記録のためのシステムモデルとSoE(System of Engagement)と呼ばれる顧客・営業のためのシステムモデルから必要なデータを取り出して蓄積するシステムです。一方の「データ分析基盤」は、データレイクのデータを表示したり、機械学習に使用したりする管理システムです。
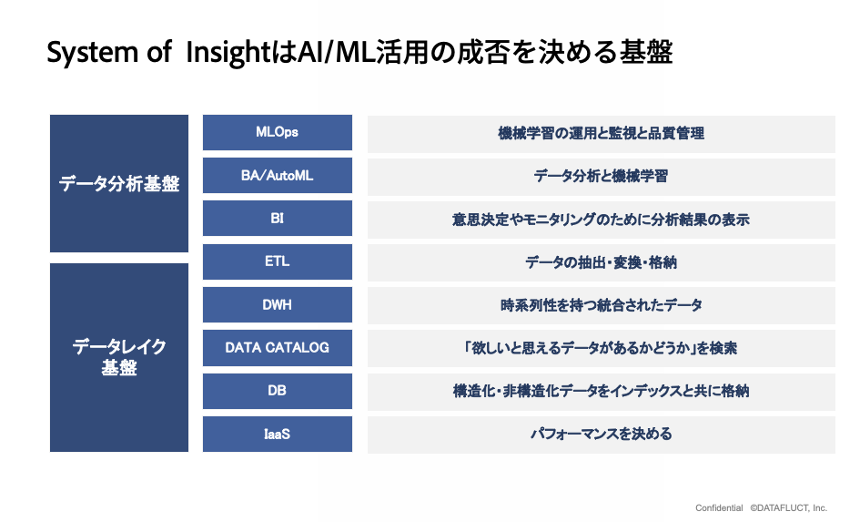
「今後のシステム投資はSoIにするべきで、この分析基盤が今後のビジネスの成否を決めます」と久米村は指摘しました。
現在の日本企業は10%程度しかデータレイクを活用できておらず、アメリカと比較すると活用企業の割合はおよそ4分の1に止まっていることが、独立行政法人情報処理推進機構(IPA)の調査「DX白書2021」でも明らかになっています。
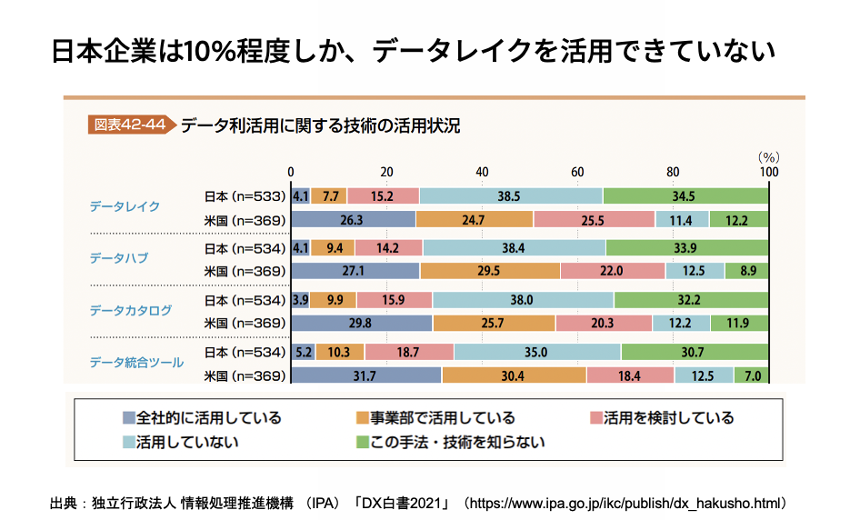
この現状を招いているのは「データの利活用文化がない」「システムの未整備」「人材確保が難しい」などの原因があることもわかっており、一気に進展させるのは難しい状況です。まずはシンプルな分析基盤を作り、徐々に拡張していく方法を久米村は勧めています。
データ基盤のアーキテクチャは変化が早く、毎年のように変わっていきます。変化の激しい部分はプロに任せるとよいでしょう。
ビジネスアーキテクチャの確立
企業の担当者がするべきことは、ビジネスアーキテクチャの確立です。その上で、競争優位になるようなデータの格納方法、運用体制、データの持ち方や種類といったデータアーキテクチャを考えるとよいでしょう。
つまりそれは、商品、顧客、販売履歴、在庫など社内でバラバラに存在するデータの中から、価値創造につながるデータを定義する作業です。最初に、マーケティング、1on1接客、サプライチェーンマネジメント(SCM)などの中からテーマを1つ決め、そのデータモデルをつくり、基盤を整備していく手順が望ましいです。
まとめると、次のようになります。
機械学習を動かすための基盤構成を理解する
いきなりDXに取り組むのではなく、ビジネスインテリジェンス(BI)やビジネスアナリティクス(BA)から機械学習へと段階を踏んで実装していく
データモデルを定義して収集・統合するデータを決めてからデータ基盤の構築に取り掛かる
「このように順を踏んで進めれば、企業の利益最大化を可能にするデータ基盤を構築できる」と、一歩一歩前進することの重要性を久米村は強調しています。
誰でも簡単に
「社内外のデータ収集」と
「非構造化データの構造化」で
データを資産化
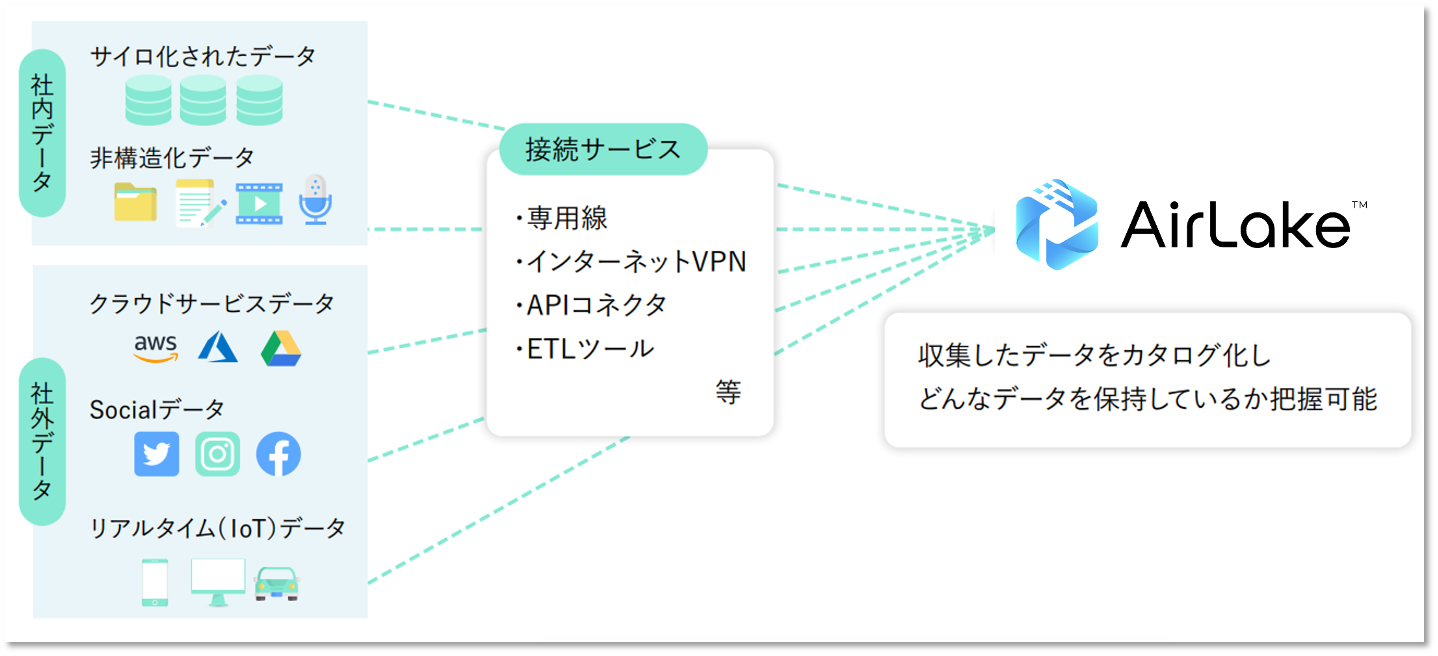
AirLakeは、データ活用の機会と効果を拡張する
ノーコードクラウドデータプラットフォームです。