AI-OCRの衝撃、精度の急拡大とRPAへの搭載で一気に実用化が進む




紙に書いてある文字などを読み込んで、デジタルデータに変換できる技術としてOCR(光学文字認識)が知られています。これまでもOCRは広く使われてきましたが、気づかない間に進化しています。
従来型技術と考えられていたOCRなどのテクノロジーも、データ活用やAIを組み合わせることで生産性が向上し、デジタルトランスフォーメーション(DX)実現に貢献するものとなっています。
OCRの歴史
OCRは歴史あるテクノロジーで1920年代にはすでにアメリカで開発されて、特許が取得されていました。日本におけるOCRの始まりは、郵便物の自動仕分けに導入する目的で開発された。「TR-4」型機という世界初の自由手書き郵便番号自動読取区分機 でした。
1980年代に入るとPCが普及し始め、OCRはPCの周辺機器として利用され始めるようになります。官公庁や銀行で伝票や各種申込書類などの読み込みが行われるようになってきました。最近では、スマホアプリとして実装されたり、PDF編集ソフトに組み込まれたりするようになっています。
2020年代に入ってクラウド化が進行するとともに、SaaSによるOCRサービスもでてきました。今後は個人やスタートアップも積極的に活用すると考えられています。
OCR使い勝手ビフォーアフター
従来OCRと言えば決まった形式の用紙に書かれた数字を読み込めるものの、自然文などは認識率が悪く、実用には限界がありました。スキャンしても間違いを探して訂正しなければならず、かえって時間がかかるので導入をやめてしまうというのが、これまでのよくあるケースだったのです。
しかし、近年は読み取り精度が向上していることで、逆に導入が加速しています。さらにOCRにAI技術を組み合わせることで、OCRが自ら学習し、生産性が飛躍的に改善しています。機械学習済みのAI搭載OCRは、文字の前後関係や読み取りの間違いを学習し、正しく変換されるように自らロジックを修正していきます。さらに、契約書・請求書など文書の種類が変わっても、原本に近い形で認識します。
このようにして、営業ノウハウなどが詰まった紙で保管していた文書を、次々と全文検索や計算に活用できるデータに変換できるようになってきました。ビジネスに関するデータを大規模分析するビッグデータの流れに乗る形で、大企業を中心に多くの企業が導入に踏み切っているのです。
国と企業が推進するDXを阻む要因として、最も大きなものの1つが紙の文書の存在です。それを一気にデジタル化するための基軸となる技術として「AI-OCR」が注目を集めているわけです。
DXにはさらにRPAも加わる
AI-OCRに、さらにRPA(Robotic Process Automation)を組み合わせる動きが強まっています。RPAとは、PCで人が行う作業をソフトウエア型ロボットが代行する技術です。

経理であれば支出入データの取り込み、伝票記帳といったルール化できる単純作業で主に用いられています。そのため、仮想知的労働者、デジタルワーカー、デジタルレイバーなどと称されることもあります。例えば銀行での口座開設において、手書き資料を処理する業務などに導入されています。
AI-OCRとRPAを組み合わせることで「紙の情報からデータを手入力する」という一連の作業全体を自動化できます。コンピュータを使った事務作業の大部分は「紙からの手入力」に絞られます。それをうまくAI-OCRで処理できれば、作業はスキャンだけで完結することになります。
受付で書いてもらう申込書、FAXで受け取る注文書、人事課が扱う各種申請書、役所での手続き書類など手書きの文書を処理する機会は世の中にあふれています。これらの業務をAI-OCRとRPAで自動化することで業務効率が上がるだけでなく、従業員は単純作業から解放され、より個人の能力を発揮できる業務に集中できるようになります。
AI-OCRの成功事例
AI-OCRは公的な組織や大企業を中心に、利用が広がっています。事例をご紹介していきましょう。
国立国会図書館
国立国会図書館(NDL)は、2022年4月にOCR処理プログラムの研究開発事業の成果である、日本語のOCR処理プログラムを一般に公開しました。これは、明治から昭和期の独特なレイアウトの本も読みこんで認識できるもので、古い資料を含めてデジタル化しようとするものです。
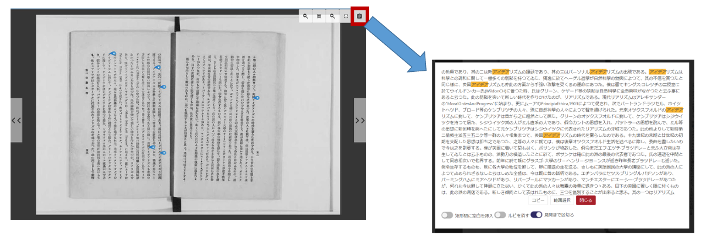
画像出所:国立国会図書館
NDLでは20年ほど前から資料のデジタル化を進めており資料をスキャンし「JPEG 2000」のフォーマットで保存する作業を進めてきました。これらは「国立国会図書館デジタルコレクション」のサイトで一般に公開されています。
紙の資料は年々劣化していくため、保存のためにはデジタル化は欠かせないと考えられています。ただし、現在の画像形式での保存では、検索性に乏しいのが欠点です。そこで、2021年からAI-OCRを利用してテキストデータ化を進めてきました。
明治期などの古い資料でも70%、最近の資料では94%の認識率をマークしたといいます。NDLの開発担当者は、検索にかけるという目的であれば、既に実用の範囲にあると考えているとのことです。
あらゆる出版物があると言われる国立国会図書館の蔵書を全文検索できるという、少し前までは考えられなかったような未来が近づいているようです。
横浜銀行
長い低金利政策のあおりを受け、銀行経営は厳しい局面を迎えています。業務の効率化は待ったなしであるため、RPAの導入も真っ先に行われてきました。
RPAの導入では、データがデジタル化されていることが大前提です。銀行は紙での業務が多く、顧客の書いた紙の申込書類や伝票類を手入力する業務がネックとなっていました。そこで出てきたのがAI-OCRです。前述の通り、以前よりも認識率は格段に上がっており、銀行の業務を自動化するのに必要十分な能力を持つと判断されたのです。
とはいえ、認識率は100%ではないため業務の流れを作って対応しました。スキャンの担当、帳票取り込み担当、修正担当の3段階です。従来は数十枚の紙の帳票をすべて手入力し、その後、人の目で点検、勘定系システムへ手入力するという手間がかかっていました。AI-OCRによってデータ化された後は、すべてRPAが作業をする流れを確立しました。
横浜市
横浜市では、保育所認定を決める時期になると業務は繁忙期に入ります。残業をした上に、他部署の応援がなければ業務が終わらない――そんな状況を解消するために、横浜市では2021年度から保育所認定に関わる業務にAI-OCRを導入しました。
確認済みの申請書類を取り込んでテキスト化した後は、RPAで自動化。時間の短縮効果は500時間にも及び、他部署の応援がなくても担当部署だけで処理できる見込みがついたといいます。
AIとOCRのこれから
情報のテキストデータ化はOCRの領域である画像からだけではなく、音声からのテキストデータ化も含まれます。AIを活用し、画像や音声、書籍などのいわゆる非構造化データの認識率を高めることが、DXの1つの大きな鍵になってきます。というのも、従来のコンピュータはその領域を扱えていなかったからです。実現すれば、生産性は大きく向上することでしょう。

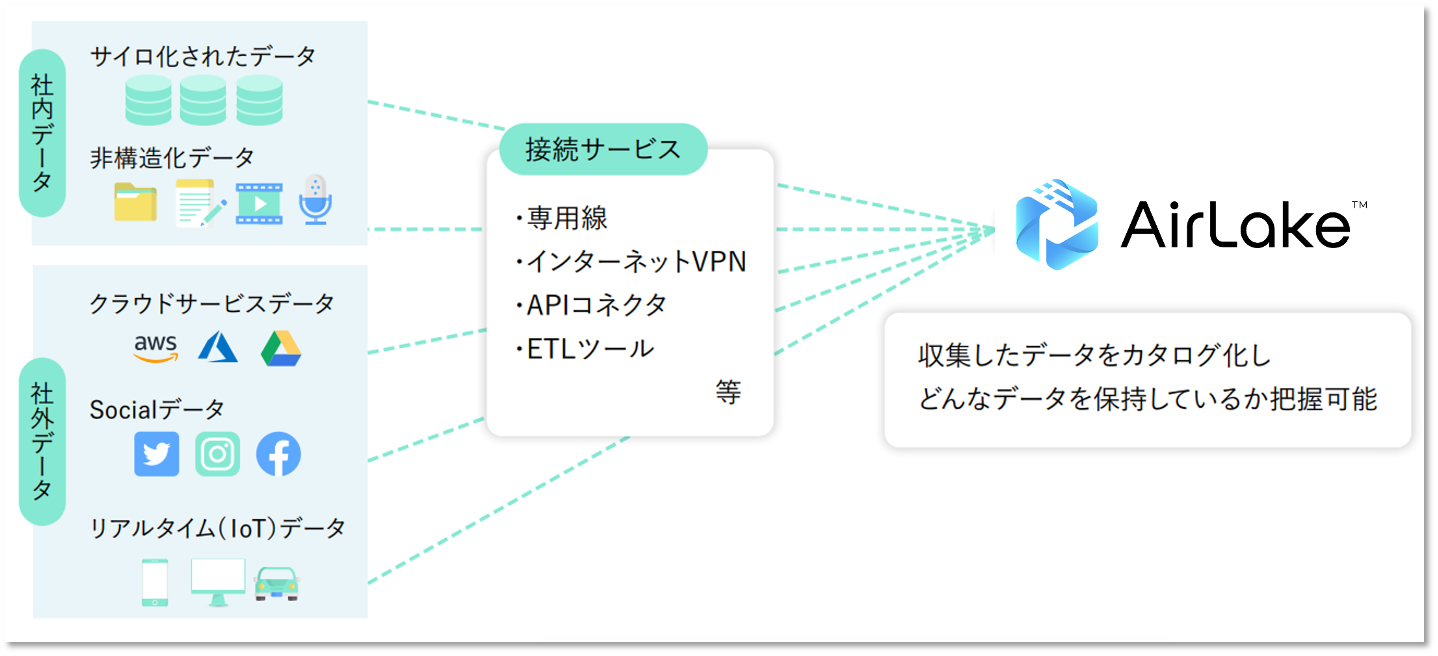
非構造化データを活用するためにはその仕組みも必要になってきます。例えば、DATAFLUCTはコードを記述することなく画像や動画、音声からのデータ活用を可能とするソフトウエア「AirLake」を提供しています。
今後DXは、企業が蓄積している非構造化データをデジタル化し、分析することでビジネスノウハウを獲得できるかに成否が左右されると考えられています。
誰でも簡単に
「社内外のデータ収集」と
「非構造化データの構造化」で
データを資産化
AirLakeは、データ活用の機会と効果を拡張する
ノーコードクラウドデータプラットフォームです。
SEやビジネスマンとしての30年にわたる経験に最新の知見を組み合わせて、各種Webメディアで執筆活動をしている。

