SRE(Site Reliability Engineering)に熱視線、運用と開発を連携する新アプローチ




急速な進化を遂げるDX(デジタルトランスフォーメーション)環境下のITエンジニアたちにとって、経験のない新たなシステムを安定稼働させていくことは簡単ではありません。運用する現場側からすればシステムは「正常に動いて当然」という感覚がある一方で、開発側からすれば「システムの信頼性を100%保証することなどできない」という本音も透けて見えます。
そこで、1つの方法論が提示されました。それが「SRE(Site Reliability Engineering)」です。SREでシステムの信頼性は確保できるのでしょうか。この記事ではSREとは何か、これまでの方法論と何が違うのか、その中身を解説し、これからのシステムの運用はどうあるべきかを考えていきます。
SREとは何か
SREは、もともとはGoogleが提唱したシステム運用の方法論です。「運用の方法論」といっても、運用だけを行う単なるオペレーションではありません。SREという考え方の上では、運用担当者はオペレーターではなく、ソフトウエアに改善を加え続けるエンジニアに近い存在になります。
Googleは検索エンジンであり、そこに掲載される広告をクリックしてもらうことによって収益を得ています。Googleのシステムがダウンするということは、本来得られるはずだった売り上げが得られなくなることを意味するため、安定稼働が命題でした。SREの“S”がSystemではなくて“Site”なのはそういった事情からなのです。

完成したシステムは、手順書に基づいてリリースされ、何らかの不具合が発生すればそれを運用担当者が復旧するのが当たり前でした。保守・運用と開発チームの役割は完全に分かれており、開発過程に原因があった場合、それを探索するのに時間がかかっていたのが現実でした。
新しい機能を次々と盛り込んでいくことでユーザーの利便性をどんどん高めていくことは、競争優位に立つ条件でもあり、ユーザーもそれを期待しています。ところが、保守・運用の担当にとってそれは同時に、どこかがダウンする可能性が増えていくことを意味し、システムの信頼性が下がっていくことと同じなのです。
次々と新しい機能が追加され続けるシステム。これをダウンしないように、信頼性が確保された状態で運用をするために考え出された方法がSREだったというわけです。
これまでの運用とどう違うのか
これまでのシステム運用は、「完成されたシステムを完全に動かす」という大前提がありました。運用の担当者はネットワークやインフラ関係のエンジニアたちであり、開発に携わっていた担当者がいるケースはまれでした。作業はすべて手順書通りに行われ、「復旧」を主として「改変」は行わないのが当然でした。
SREではこうした信頼性を担保する保守的な側面を保持しつつ、繰り返し行われる作業は自動化したり、目標とする性能が出ていない場合は、設計し直したりするなど「変化させる」という意味で“攻めの姿勢”が見られます。
こうした観点から、従来の運用が「保守的」な運用方法であったのに対し、SREは「革新的」に運用していく姿勢を明確にしていると言えます。従来の運用の延長線上にある方法論ではないのです。
開発する側と運用する側の利害が対立するような場面は多々ありますが、システムをうまく運用し成果を出すには協力関係を築くことが必要です。開発(Dev)と運用(Ops)による協力関係の好循環を作り、リリースサイクルの短縮化を図ろうというのが、すでに知られている「DevOps」という考え方です。
SREはこれを、システム全体の信頼性の確保のため進化させたものであるともいえます。
“Reliability”=「信頼性」をどう評価するか
SREの“R”は“Reliability”(信頼性)を指します。SREにおいて信頼性は以下の3つの指標で評価されます。
・SLA(Service Level Agreement):サービスレベル保証
自らのサービスレベルを対外的に保証する値で、これが満たせなければ返金などの補償問題が発生します。
・SLO(Service Level Objective):サービスレベル目標
自らのサービスレベルの目標としている値で内部的なもの。
・SLI(Service Level Indicator):サービスレベル指標
何をもってシステムの良しあしを判断するのかその指標
対顧客に対して約束するレベルを定めたものがSLAであるのに対し、自社のシステムはどれくらいの信頼度であればよいのかについて定めた目標値がSLOで、SLOをどうするのか指標を定めたものがSLIです。
自社のシステムがどれくらいの信頼性を持てばよいのかということについてSLOに定めることになりますが、その中の1つに「エラーバジェット」という考え方があります。Googleでは「ユーザーが不満を感じ始めるまでの一定の期間にサービスで累積できるエラーの量」と定義していますが、一般には「システムに不具合が生じていた時間の予算」だといわれています。
これが多すぎる場合、反比例して新規開発の時間は減っていきます。システムをエラーなく動かすほうに時間を使うべきだということになるわけです。逆にエラーバジェットが余ればその分新しい機能の開発に時間を割けるということになります。
SREを向上させる方法
システムが複雑化する現代では、SREを自らのシステム運用に取り入れたいと思う企業は増えるでしょう。SREを向上させるためにはどのようなアプローチが必要となるのでしょうか。
米Constellation Research社のAndy Thurai氏は、これは技術的な手法だけで解決できる問題ではなく、いくつかの要素が求められます。
組織
SREにはまず組織が必要になるといいます。まずIT部門と現場部門がそれぞれの「サイロ化」から脱却し、コラボレーションする必要があるのです。特にIT部門は自らを「特殊な組織」と位置付ける傾向もあると言われているため、注意が必要です。
いまやITは収益と直結しています。そうした意味からすると「原価部門」であることも意識する必要があります。現場部門に対し、決して技術的な都合を押しつけることなく、運用は1つのチームとして行う考え方に立ちます。
これには、システムに関する懸念や問題はオープンに話し合える環境をつくり、相手の立場に立って共に考えられる組織にし、その自主性を重んじて継続的な向上を図る必要があります。
人材
SREにあたるチームを構成する人員構成は、インシデントの洗い出しやエスカレーション、人手による対応を中心に考えるべきだとしています。チームが活動するうちに、そうした大変な作業は少なくなっていくので、自動化や生産的な作業に集中できるようになります。
最初から満点を求めるのではなく、自ら成長し、経験値を積んで高い機能を発揮するチームを目指した方がうまくいくと考えられています。
適切なツール
システムの状態の監視やインシデント発生の予測のために、適切なツールを導入することが有効かつ重要な手段になります。クラウド化が進み、デジタル効率の高い組織が求められる現代のシステムには、それに合った危機管理の手法があります。特に求められているのが、インシデント発生を事前に予測し、対策することです。
自動化
SREに各種の自動化は必須です。需要の増減に合わせたシステムの拡大・縮小、コンテナベースのシステムに不可欠なKubernetes によるオーケストレーションやクラスター管理に加え、シンプルな対処を自動化することは、エンジニアの手を煩わせることをなくしていきます。
AIとMLの導入
インシデント疲れという言葉もありますが、すべてのインシデントに目を通し、対処することは困難です。AI(人工知能)やML(機械学習)を活用する運用として「AIOps」が登場しました。これにより、人間と機械が知力を組み合わせ、重要でないインシデントを排除し、本当に対処すべきインシデントに集中できるようになります。

運用方法もトランスフォーメーションが必要なのか
クラウド化の進展もあり、システムの在り方は短期間で大きく変化しました。それに伴って運用方法も大きく変化しているといえるでしょう。現代のシステムは常に未完成であり、進化し続けるため、運用側もそれに合わせざるを得ません。
SREは、時代の変化に合わせて登場した考え方であり、今後も変化していく可能性があります。現代のコンピュータシステムに対する向き合い方に関しては、過去にとらわれない柔軟な対応が求められるでしょう。
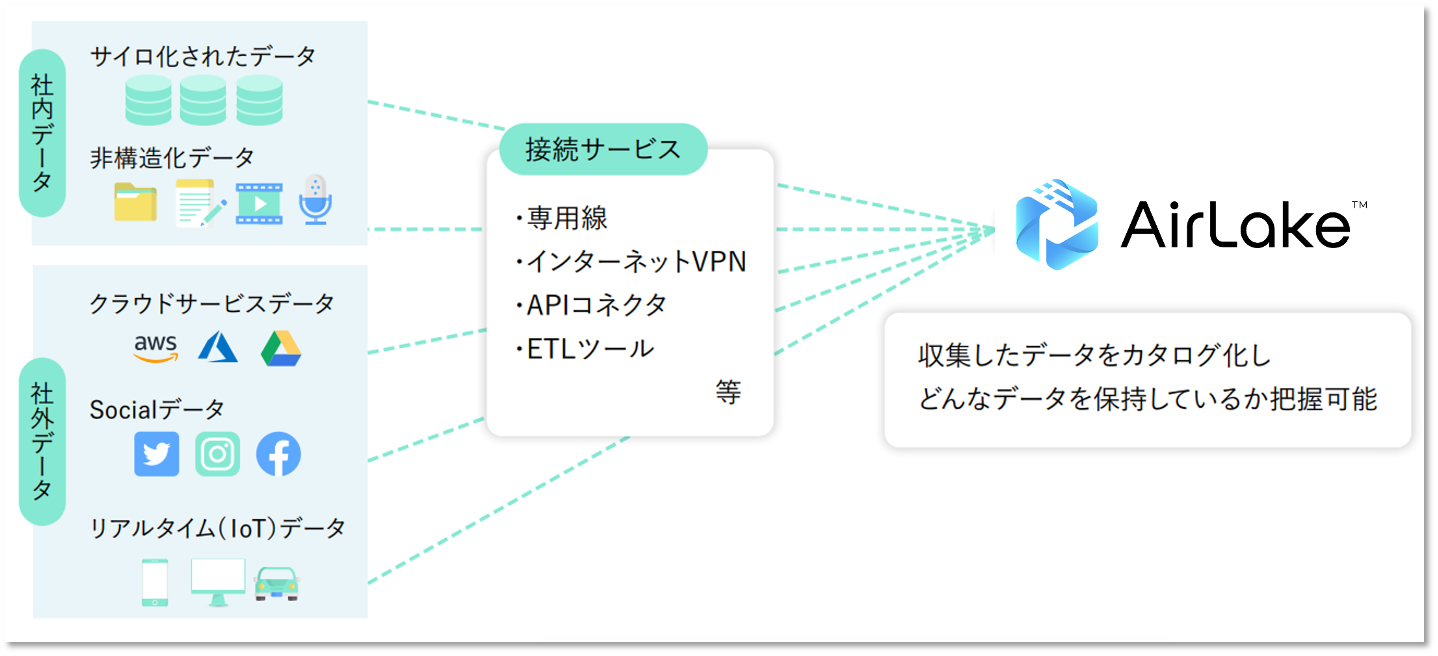
誰でも簡単に
「社内外のデータ収集」と
「非構造化データの構造化」で
データを資産化
AirLakeは、データ活用の機会と効果を拡張する
ノーコードクラウドデータプラットフォームです。
SEやビジネスマンとしての30年にわたる経験に最新の知見を組み合わせて、各種Webメディアで執筆活動をしている。

