製造業のIT×OTデータ統合基盤の構築とその活用(3) データレイクによる強みと競争力向上 ~ユーザー側と経営側のメリットから実現~




連載の2回目では、IT×OTデータレイクを構築しているデンソー、AGC、横河電機の3社について、取り組みの概要を紹介しました。デンソーは自動車部品メーカー、AGCはガラスなど素材メーカー、横河電機は計測機器や工場関連のエンジニアリングメーカーとして、国内外に幅広く展開しています。今回は、その具体的な内容について説明するとともに、IT×OTデータレイクが、他社との差別化にどのような役割を果たしているかを考察します。
IT×OTデータレイクのユーザーに対するメリットと期待効果
IT×OTデータレイクを導入する製造業が、その効果として必ずと言っていいほど強調するのが「ユーザー自らによるデータ活用」です。
これは、社内の経営情報(ERP)、事業部情報(ERP)、工場情報(MES/MOM)、在庫・物流情報(WMS/LES)などが必要なときに即時に入手できるデータ利用環境が整っていることを意味しています。この仕組みを理解するためには、データレイクとデータウェアハウスの違いを把握しておく必要があります。
データレイクとデータウェアハウスの違いは「加工していない生データを蓄積するデータレイクに対し、整理したデータを蓄積するのがデータウェアハウス」と表現できるでしょう。以下、その役割の違いを簡単に説明します。
データレイクの役割
データレイクは、収集した生のデータをファイルとして格納し、データ資産として保管する役割を担います。データレイクに格納されるデータは、構造化された数値や値などに加えて、テキスト、画像、動画、音声といった規則性を持たない非構造化データも含みます。データレイク内の非構造化データは活用するときに、都度構造を定義します。その上でデータを参照し、分析結果を得られます。データレイクの手法は、ビッグデータの分析処理でよく利用されています。
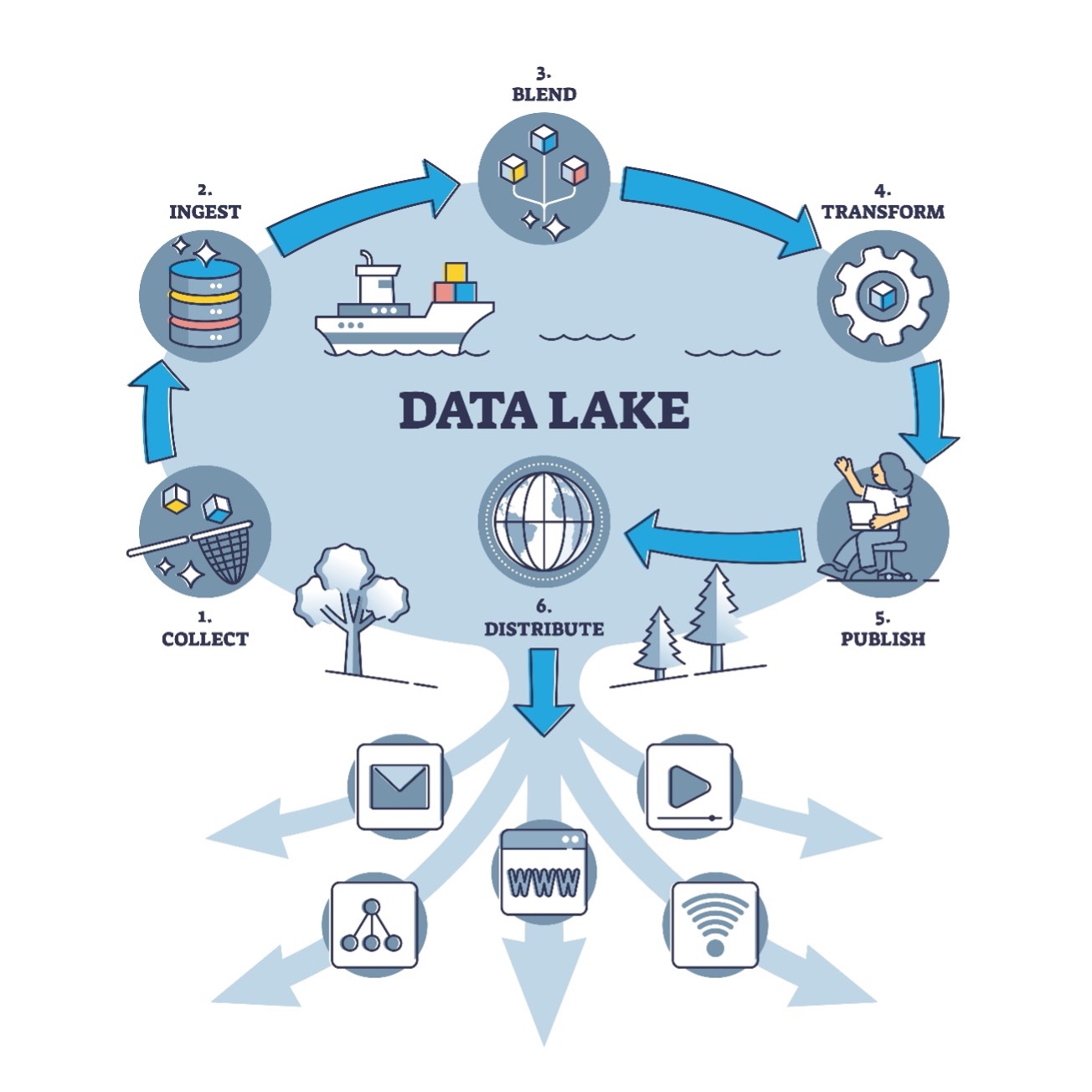
さまざまなデータを集め、ためるのがデータレイク
データウェアハウスの役割
データウェアハウスは通常、基幹系システムから独立したデータベースとして構築されます。そして企業内で営業や経営(経理)など部署ごとに分かれた複数の業務システムやデータベースからデータを集約します。そうして集められたデータはサブジェクト(主題)ごとに、時系列に従って分解・整理して蓄積していきます。

データウェアハウスは、データレイクなどのデータソースで集めたデータを分析用に加工する
つまり、データレイクの構築に社内外のデータがそろっているので、これを整理区分して正規化したデータにすれば、誰でもビジネスインテリジェンス(BI)ツールを使ってデータの可視化や分析レポート作成、データを利用したアプリケーション開発(ウェブアプリやスマートデバイス用アプリ)をセルフサービスで開発できます。
基本的に、こうしたシステムの開発を外部ベンダーに依頼していましたが、時間とコストが掛かること、機密性の高いデータが社外に流出してしまうリスクがあることなどから、データ活用について内製化を進める製造業もあります。
また、バラバラに開発した分析システムは、同じ情報を扱っているはずなのに、システムごとに差異が生じることが問題となっています。例えば、原価などの情報について、ERPと工場別の原価システムで差異があるといったケースです。その原因は、元ネタとなる原価データを「どこから、どのタイミングで、どう取得、処理したのか」に違いがあるからです。元ネタを全てデータレイクに格納するようにすれば、こうした差異はなくなります。
IT×OTデータレイク導入は、データを利用するために必要なデータウェアハウスの正確性の確保と正規化に有効です。ユーザーがBIツールを使って、整っているデータを必要なときに即時に使えるデータ利用環境が整っていることになります。
工場間のOTデータレイク導入プロジェクト
筆者が関わった工場間のOTデータレイク導入プロジェクトでは、BIツールとデータ利用の権限を、生産技術本部が統括していました。これによって、工場間で取得するデータを標準化し、工場間でデータの内容、頻度、品質、ボリューム、環境データなどのギャップをなくすことができます。
さらに、データの整理、データの正規化、データの利用権限などを一元管理できます。新しいセンサーやRFID、カメラなどの導入やデータ取得やセキュリティ対策などの直接窓口となります。この生産管理本部が、データレイクやデータ活用の統括となるので工場や研究所、事業部門などにデータ利用ノウハウ(BIツールとデータ利用権限)を展開する役割も担っています。
これによって、ユーザーはセルフサービスでBIツールを使い、最新のデータを利用できます。データ品質、データ容量、最短スピートによる情報活用は、そのまま業務の強みとなります。多くの企業で、これまでは別々の部門やシステムで管理されていたデータに、相関性が見つかって新しく独自AIのアルゴリズム開発などに活用されたり、カイゼンやコスト削減に有効なパラメータが発見されたりなど、顧客向けの新しいサービスによる顕著な効果が出ています。

IT×OTデータレイクによる経営管理のリアルタイム双方向マネジメントの実現
製造業において、経営層が入手できる工場の情報は計画と実績だけでした。計画データは、実際にはそのときの状況によってきめ細かく修正や変更が入ります。週、日、時間という細かいレベルで変更されるため、当初の計画と乖離(かいり)することも多々あります。昨今では、原材料の調達がコロナ禍や紛争などによって生じるサプライチェーン混乱で変更・遅延することも多くなりました。
したがって、生産実績の情報は当初計画とは大きく異なった内容となっています。さらに、これまでは生産が終わってから実績となる生産数量をカウントしてから報告が出るため、生産進捗は完全にブラックボックスとなっていました。経営と工場がそれぞれ一方通行にデータを送っている状況だと言えます。
これは経営からの生産計画と工場からの生産実績がバラバラで、そのデータも月1回、週1回という頻度でした。これでは、目まぐるしく変化する昨今の状況を機敏に経営判断するのは困難です。さらに、生産進捗が把握できないため、生産現場の問題を経営がタイムリーにサポートすることもできません。MES/MOMやOTデータレイクは、生産進捗を把握する元ネタとしても重要なデータです。
生産進捗の把握(参考例)
オーダーからの製造指図から、生産工程が10ほどある場合、各工程の標準生産時間を全て1日と仮定すると、生産計画としては10日必要です。実際には、生産設備の稼働状況や優先順位によって遅延するケースもあります。5工程目が終わって6日たっていた場合は、進捗率は50%で、遅延1日となります。オーダーごとの進捗率と遅延日数をMES/MOMから自動的にデータで取得できれば、経営は現場に問い合わせることなく、大体の進捗状況を把握できます。
これを踏まえた上で、さらに詳細な情報を現場管理者へ問い合わせることで、経営判断に有効な情報をピンポイントに集められます。OTデータレイクやMES/MOMは、経営と工場の双方向の情報共有を担います。
グローバル展開しているメーカーは、世界各国に生産拠点や物流拠点を持っています。自社工場で内製化するケースと協力会社による委託生産を行うケースが混在していて、1つの工場、生産ラインで1つの製品を作って市場へ供給するスタイルではなくなりつつあります。これからのものづくりでは、複数の工場で役割分担(工程分業)して納期、コスト、リードタイム、サステナビリティなどに合わせた生産が求められます。
こうした複数の生産拠点とサプライチェーン全体を考慮した生産管理は「工場のオーケストレーション」と呼ばれています。音楽会のオーケストラと同じように、生産管理本部が指揮者となって、世界各国の生産拠点の動きに目を配ってオーケストレーションします。IT×OTデータレイクの経営管理におけるメリットは、状況変化に対応できる経営コントロールを実現することです。
今回は、IT×OTデータレイクのユーザーメリットと経営メリットについてお話しました。特に、ユーザー、経営それぞれのメリットと期待する効果について深掘りしています。これは、製造業のサービス化やアプリケーション開発につながるポイントです。
さて、次回はIT×OTデータレイクを構築するプロジェクトの体制と、IT系システムとOT系システムと蓄積されたデータの正規化について、筆者の構築経験から解説します。
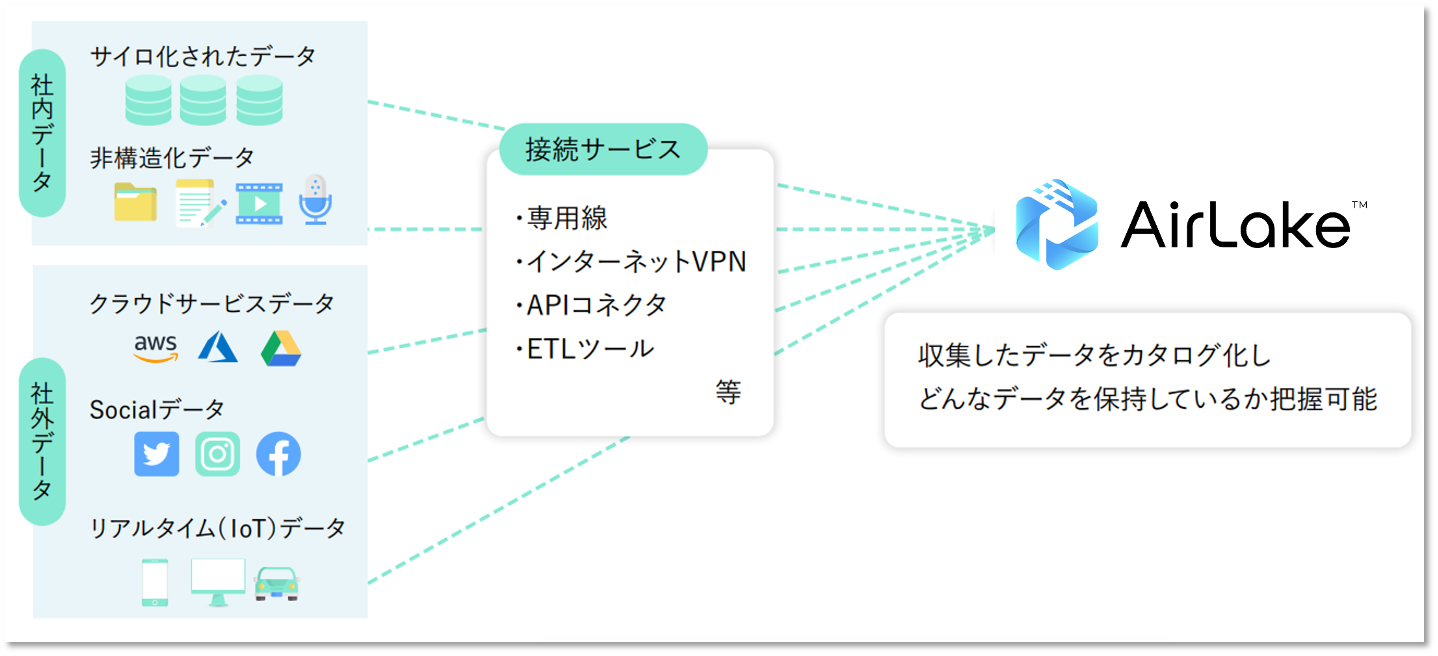
誰でも簡単に
「社内外のデータ収集」と
「非構造化データの構造化」で
データを資産化
AirLakeは、データ活用の機会と効果を拡張する
ノーコードクラウドデータプラットフォームです。